xAI today released Grok4, its latest model. Elon Musk spoke highly of the model, calling it capable of “superhuman reasoning” and said that it was equivalent to a PhD in many fields. But where the model really shone out was in its benchmark results. AI models are given standardized tests, and their scores on these benchmarks can help users determine their relative abilities.
Grok4 Benchmarks
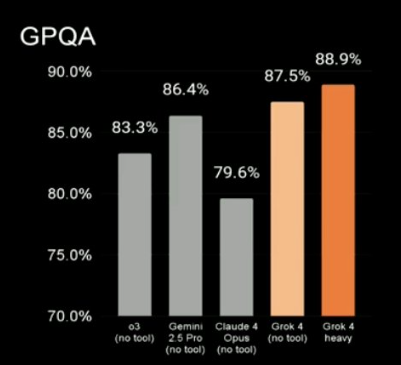
On the GPQA benchmark, Grok4 topped the charts. GPQA Diamond is a subset of 198 challenging, multiple-choice questions from the GPQA (Graduate-Level Google-Proof Q&A) benchmark. These questions are designed to test the reasoning abilities of AI models in biology, physics, and chemistry at a graduate level, requiring genuine scientific expertise rather than simple search skills. On this model, Grok4 scored 87.5%, while Grok4 Heavy scored 88.9%. Both these results were better than the results obtained by top models from other companies. On the same benchmark, Claude 4 Opus had scored 79.6%, Gemini 2.5 Pro had scored 86.4%, and OpenAI’s o3 had scored 83.3%.
The American Invitational Mathematics Examination (AIME) is a prestigious, invite-only mathematics competition for high-school students who perform in the top 5% of the AMC 12 mathematics exam. Grok4 Heavy managed to saturate this benchmark, scoring a perfect 100% score. Grok4 scored 98.8%, and Grok without tool use scored 91.7%. In comparison, OpenAI’s o3 had scored 98.4, Gemini 2.5 Pro had scored 88%, and Claude 4 Opus had scored 75.5%.

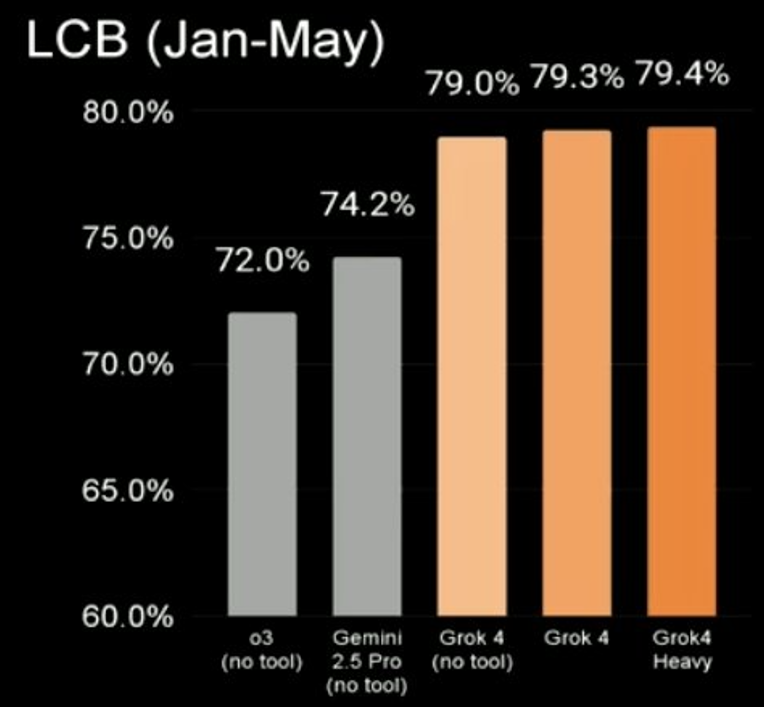
LiveCodeBench is a coding benchmark, and collects problems from periodic contests on LeetCode, AtCoder, and Codeforces platforms. On LiveCodeBench, Grok4 again topped the charts, with Grok4 Heavy scoring 79.4%, Grok4 with tool use scoring 79.3%, and Grok4 without tools scoring 79%. In comparison, Gemini 2.5 Pro had scored 74.2% on the same benchmark, while OpenAI’s o3 had scored 72%.
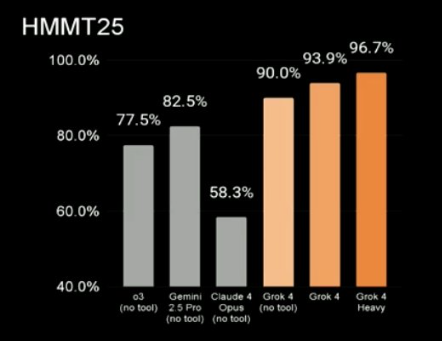
The HMMT is a prestigious math exam for college students. On the benchmark, Grok4 Heavy top-scored with 96.7%, Grok4 managed 93.9%, and Grok4 without tools scored 90%. In comparison, Gemini 2.5 Pro had scored 82.5, and OpenAI’s o3 had scored 77.5%.
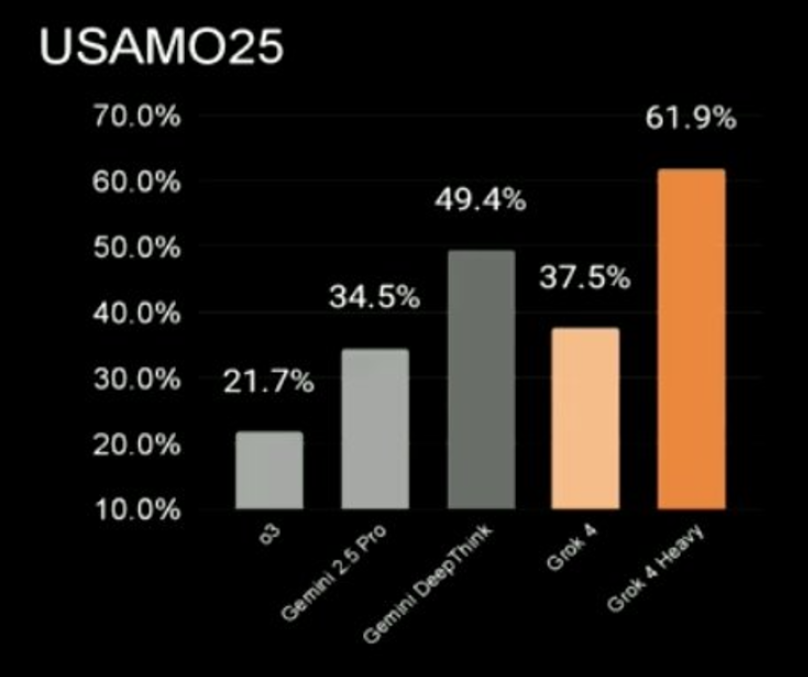
The USA Mathematical Olympiad consists of very hard problems in mathematics, which even top mathematicians struggle to solve. On this benchmark, Grok4 Heavy managed 61.9%. Gemini DeepThink was second with 49.4%, and Grok4 managed 37.5%. Gemini 2.5 Pro was at 34.2%, and OpenAI’s o3 was at 21.7%.
On ARC-AGI — which is a dataset of puzzles to determine if we’ve reached AGI — Grok4 performed head and shoulders above its peers. While no other model had broken the 10% level, Grok4 scored 15.9% on the ARC-AGI v2 semi private exam. In comparison, Claude Opus had managed 8.6%, OpenAI’s o3 had managed 6.5%, and Gemini 2.5 Pro had scored 4.9%.

These are extremely impressive benchmark results, and show how Grok4 is decisively now the best AI model around. But competition in the space is fierce — OpenAI is set to release GPT-5, and there are rumours that Google could soon release Gemini 3. It remains to be seen for how long Grok4’s benchmarks remain top of the pile, but for now, it’s managed to decisively create a new state-of-the-art in AI model performance.